
Your AI Infrastructure Partner
Purpose-built infrastructure where energy, cooling, and compute converge to produce intelligence at scale. Deploy the models that define the next decade of AI with guaranteed power and zero egress fees.

Peak performance,
Built for the Agent Era
Highest performance.
Full-stack optimization from power to compute to orchestration. 94% GPU utilization. Purpose-built infrastructure ready for tomorrow's models and superintelligence.
Any agent.
Deploy OpenAI, Llama, DeepSeek, or your own custom models. Kubernetes-native infrastructure with auto-scaling and built-in orchestration. Open platform that adapts to your requirements.
Your control.
Deploy in jurisdictions you control, with guarantees your data stays within your borders. Confidential computing for defense, intelligence, and enterprises requiring full control over proprietary IP.
AI cloud platform
Enjoy direct access to GPU clusters ranging from 8 to over 10,000 GPUs. They are InfiniBand-connected for maximum training performance. Choose from reserved, on-demand or spot pricing.
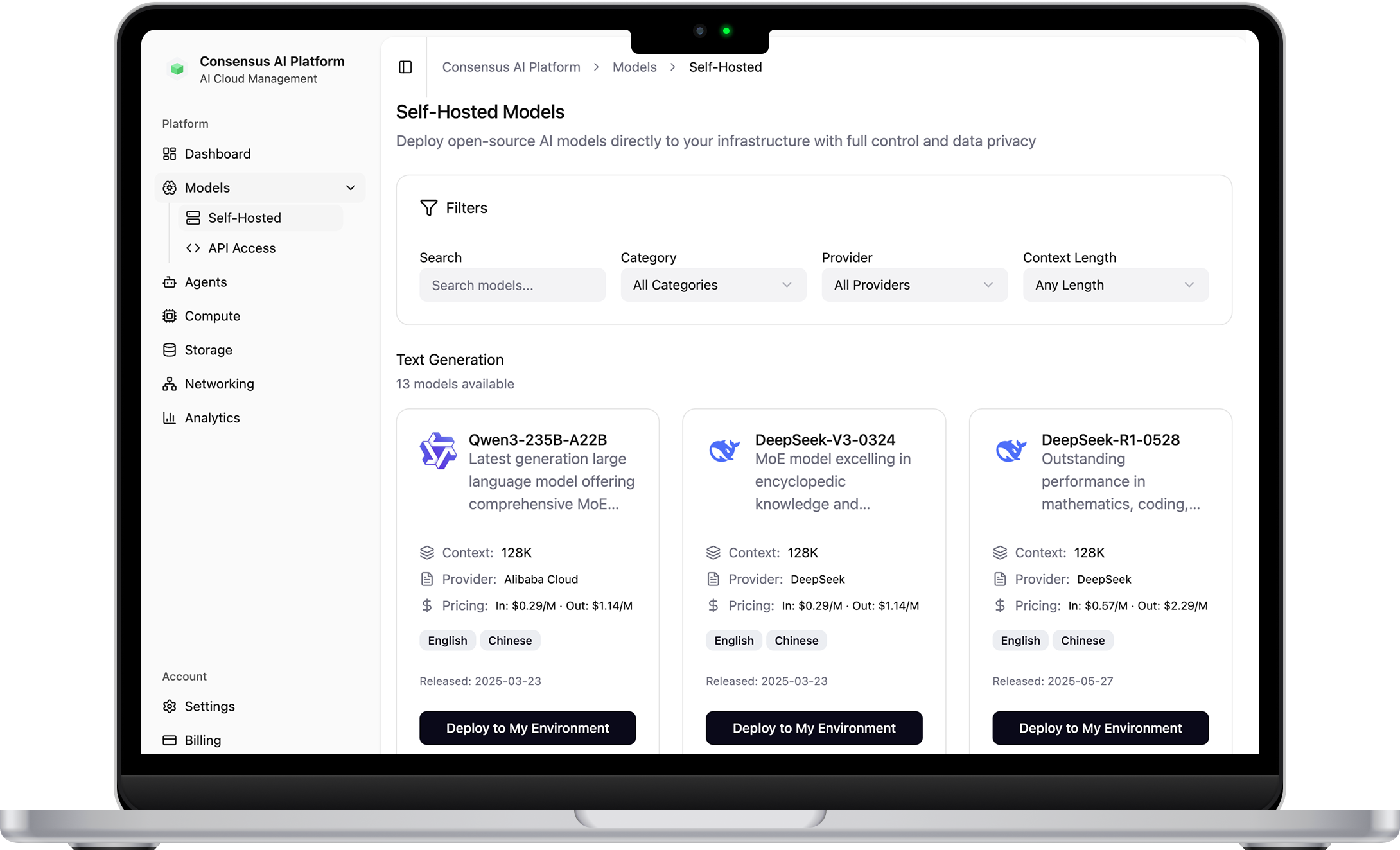
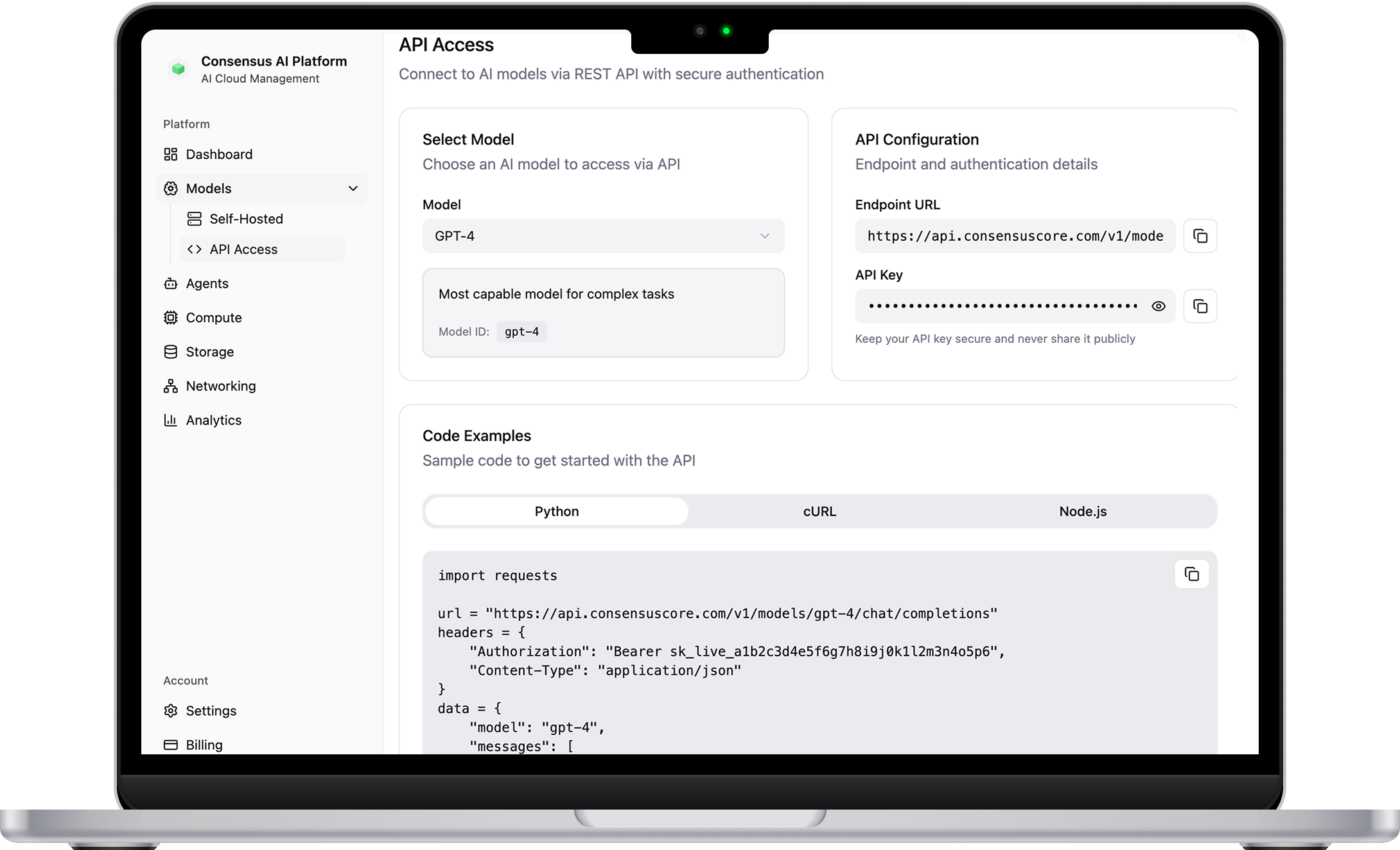
Full Control Without Infrastructure Overhead
Kubernetes-native platform with auto-scaling and intelligent load balancing. 3-5x faster container spin-up than hyperscalers. Deploy any model, open-source or proprietary—without managing infrastructure.
Intelligence on Demand
Production-ready endpoints for Llama 3.3, Mistral, DeepSeek, and frontier models. Automatic scaling handles traffic spikes. No GPU management, no surprise bills—just intelligence on demand.

Ready for Superintelligence
Direct access to supercomputer-scale clusters. InfiniBand-connected H100, H200, B200, GB200 for distributed training. Reserved, on-demand, or spot pricing to match your workload economics.
“
Consensus Core’s innovative solution fills a critical gap in the market, empowering businesses of all sizes to leverage the immense power of AI and machine learning.

Our North American Footprint
Manitoba:
High-Density Campus Expansion
A ~350-acre contiguous campus currently advancing through design and commercialization initiatives with prospective hyperscale tenants. Selected for near-term power access, the site sits adjacent to major electrical and regional utility infrastructure, offering a rapid path to capital-efficient deployment.
.webp)
Texas: Accelerated U.S. Deployment
Designed to immediately expand our operating footprint, this site provides the fastest path to mass capacity with immediate megawatts available via pre-existing, energized infrastructure. This expansion broadens our geographic footprint, securing U.S. data residency and long-term capacity for enterprise and government workloads.


Reserve NVIDIA GB200 NVL72 Supercomputers
Trillion-parameter training and real-time reasoning require more than just GPUs—they require a supercomputer-in-a-rack. With 72 GPUs, 120kW liquid-cooled racks, and NVLink interconnects running at 900 GB/s, the GB200 is built for the models of tomorrow. Secure your capacity on our infrastructure today.


Talk to an expert
Our cloud includes the new NVIDIA H100 Tensor Core GPUs (PCIe) which offer unprecedented performance, scalability, and security for any deep learning workload.